
Als klassieke visietechnieken tekort schieten…
Hoe kan een machine dankzij visietechnieken een krat correct herkennen? Zelfs als die kratten er anders uitzien en bedekt zijn met stickers? En is dat dan een voorbeeld van artificiële intelligentie, machine learning of deep learning?
Er bestaat heel wat verwarring rond de concepten artificiële intelligentie (AI), machine learning (ML) en deep learning (DL). Het is belangrijk om te begrijpen wat de verschillen zijn en hoe ze toegepast worden.
Artificial intelligence: de koepelterm
AI kenmerkt een systeem dat karakteristieken van menselijke intelligentie vertoont. Het wordt meestal gedefinieerd als het vermogen om taken of een redenering uit te voeren op een manier die gelijk is aan hoe wij als mens dat zouden doen.
Machine learning: onderdeel van AI
ML wordt vaak onterecht gebruikt als synoniem voor AI. Maar ML is in feite een onderdeel van AI. Een subset. Het hoofddoel van ML: algoritmes creëren die output genereren op basis van input, met behulp van statistische analyses.
ML wordt meestal ingezet om patronen te ontdekken in grote datasets en daar de output op af te stemmen. Bij online shoppen worden bijvoorbeeld producten aangeboden die passen bij uw aankoopprofiel. Dit zijn dan eigenlijk resultaten van een statistische analyse, waar een wiskundige basis onder ligt.
Samengevat: ML omvat dus algoritmes die de mogelijkheid hebben om zelfstandig bij te leren, zonder dat deze expliciet geprogrammeerd moeten zijn.
Deep learning: onderdeel van ML
DL is dan weer een subset van ML. Deze algoritmes gaan nog een stuk verder dan de meeste ML- algoritmes, en zullen zichzelf in zekere mate opbouwen. DL-algoritmes maken gebruik van artificiële neurale netwerken, die leren aan de hand van grote hoeveelheden data (“Learn by Example”).
Neurale netwerken zijn ook de bouwblokken van het menselijk brein. Het principe is heel vergelijkbaar met hoe mensen leren: hoe meer voorbeelden, des te accurater de conclusies.
Net zoals bij een pasgeboren kind. Zodra ze het gezicht van hun ouders zien, beginnen ze met het leren herkennen. In het begin zullen ze fouten maken, maar naarmate tijd verstrijkt worden ze hierin steeds beter. Dit komt omdat we steeds beter leren te ‘herkennen’ op basis van wat we al ervaren hebben en weten (opgeslagen hebben). Zo leren we onze ouders bijvoorbeeld ook te herkennen aan hun stem. En als we ouder worden, werkt dit precies hetzelfde met taal, cijfers, letters en vervolgens leren lezen en schrijven. Alles draait om patroonherkenning!
Van terminologie naar oplossing
Voor Deep Learning-oplossingen bij klanten gebruikt VistaLink NV een softwareprogramma ViDi. Dit programma is ontwikkeld door Cognex en ontworpen om computers, machines en robots in staat te stellen beelden te begrijpen, zodat ze zinvol kunnen interageren met de echte wereld.
De drie delen van CNN
Zo een DL-software maakt gebruik van een algoritme dat Convolutional Neural Network wordt genoemd. Of in het kort: CNN. Dit type algoritme is gebaseerd op de manier waarop informatie wordt doorgegeven en verwerkt door het netwerk van neuronen in het menselijk brein. Vandaar dat u soms ook de term neurale netwerken tegenkomt als men over Deep Learning spreekt.
In het algemeen bestaat zo’n CNN uit drie delen:
- een inputlaag
- een aantal verborgen lagen (neurale netwerken)
- een outputlaag
Voor de gebruiker zijn alleen de input- en outputlagen bekend. Zoals de naam al aangeeft, kunnen de verborgen lagen worden opgevat als een zwarte doos, waarvan de precieze aard en inhoud voor de gebruiker verborgen blijft.
De werking van CNN
Deze verborgen lagen vormen de kern van het DL-proces. Simpel gezegd verwerkt het algoritme de aangeleverde inputinformatie. Op basis hiervan kent het aan elk deel van het beeld gewichten en kenmerken toe, die worden doorgegeven aan de volgende laag.
In de volgende laag herhaalt dat proces zich. En hoewel deze gewichten aanvankelijk vrij willekeurig worden toegekend, zal het netwerk na verloop van tijd leren aan welke kenmerken en welke delen van de beelden het een hoger gewicht moet toekennen.
Afhankelijk van de complexiteit en het aantal kenmerken dat moet worden gevonden, kan het vereiste aantal inputbeelden variëren van een paar 100 tot 100.000 beelden. Na de training, moet het CNN in staat zijn om (delen van) nieuw toegevoegde beelden, waarop geen training is uitgevoerd, te verwerken en correct te identificeren.
Belang van beeldkwaliteit
Aangezien het volledige netwerk wordt opgebouwd op basis van de aangeleverde beelden, is de beeldkwaliteit uiteraard van vitaal belang. Beelden moeten genomen worden onder dezelfde omstandigheden als waarin het netwerk zijn taken zal uitvoeren tijdens productie.
Binnen beschikbare DL-software bestaan meestal verschillende tools die een specifiek toepassingsgebied hebben. Sommige tools focussen zich op beeldclassificatie waar op basis van een geclassificeerde trainingsset het algoritme in staat is om zelf accuraat te discrimineren tussen verschillende objectklassen.
Zo zijn er ook tools voor optische tekenherkenning (OCR) of lokalisatie van objecten of kenmerken. Als laatste zijn er tools voor foutendetectie. Deze werken in twee modi: een modus Unsupervised en een modus Supervised.
Unsupervised
Wanneer niet gesuperviseerd wordt gewerkt, is de hoeveelheid tijd en moeite die door de gebruiker moet worden besteed, beperkt. Op basis van de door de gebruiker als goed geclassificeerde beelden, leert de DL-software welke beeldkenmerken niet overeenkomen met een goed product en geeft deze aan als defecten. Op basis van de score die het netwerk toekent aan elk van de afbeeldingen (op basis van de aanwezigheid van het defect, de hoeveelheid ervan en de soort), zal de afbeelding worden geclassificeerd als goed of slecht.
Supervised
In de gesuperviseerde modus is het model gebaseerd op beelden van slechte monsters. Meer bepaald op de precieze aard van de defecten die in deze beelden aanwezig zijn. Dit betekent dat het model alleen zal zoeken naar defecten die lijken op die welke het heeft geleerd. Willekeurige afwijkingen zullen onopgemerkt blijven. In dit geval neemt de arbeid die van de gebruiker wordt verwacht om het model te kunnen trainen aanzienlijk toe.
Voor de meeste situaties worden de verschillende tools gecombineerd gebruikt. Om de meest optimale en volledige inspectie te verkrijgen voor elk individueel doel.
Praktijkvoorbeeld: kratten
We verduidelijken zo’n DL-toepassing met een praktijkvoorbeeld. Kratten met verschillende groottes, vormen en kenmerken moeten correct gedetecteerd en geteld worden. Kratten die verschillen qua
- uitzicht,
- inhoud,
- kleur,
- de aanwezigheid van restanten van stickers of gebruikte papieren flappen
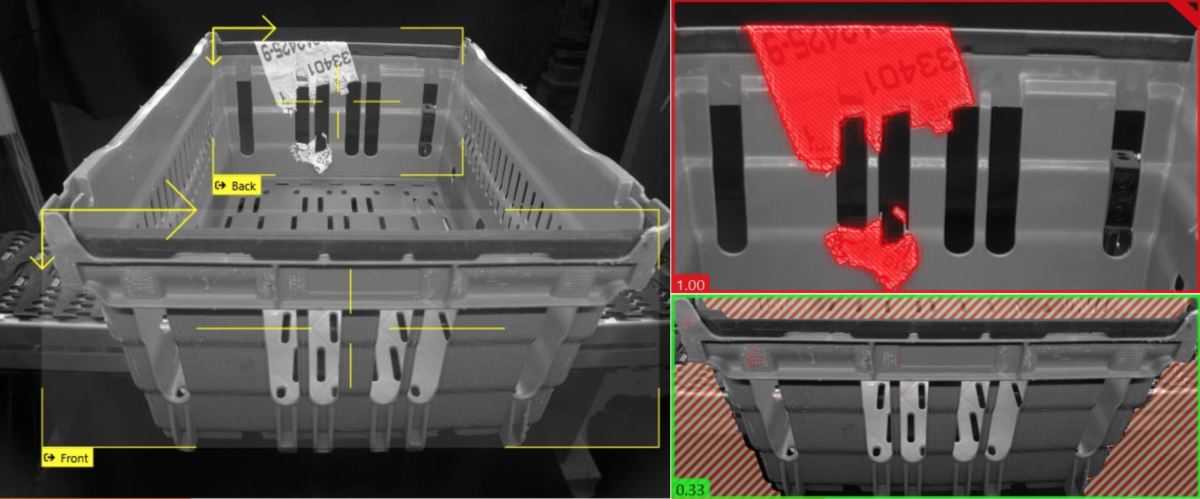
Vanwege die variëteit kan dit niet met klassieke visietechnieken opgelost worden. Om de kratten toch correct te kunnen identificeren, wordt elk type voorgesteld door een model opgebouwd uit kenmerken. Deze kenmerken zijn herkenbare onderdelen van een krat, zoals bijvoorbeeld een letter of een kruising van ribben.
Tussen deze kenmerken wordt dan de onderlinge relatie vastgelegd in afstanden en hoeken ten opzichte van elkaar en de toegelaten variatie. Op basis daarvan kunnen volledige kratten geïdentificeerd worden.
Het voordeel van deze methode, vergeleken met een volledig krat als één kenmerk aan te leren? De variabiliteit die kan worden toegelaten. Onder andere door het verschil in perspectief boven- en onderaan de stapel ten opzichte van in het midden.

Bij deze vier kratten, ten slotte, merkt u onderaan een moeilijke situatie. De rechtse kratten zijn volledig zichtbaar, maar de linkse kratten zijn deels bedekt. Bij de bedekte kenmerken wordt de blauwe aanduiding met een stippellijn omrand, omdat ViDi deze niet ziet, maar op basis van de wel gevonden kenmerken van dit model veronderstelt dat ze op deze plaats zouden moeten zitten. Alle vier de kratten worden op deze manier correct gevonden.

Een zo breed mogelijke kijk op machinebouw en retrofit is de beste garantie op succes. Daarom geven we in deze artikelreeks het podium aan een andere expert binnen ons brede domein.
Dit artikel is geschreven door Vistalink, onderdeel van cxv global. Vistalink levert technologische oplossingen op het gebied van IT & Real Time Automation, Machine Vision, Serialisatie, Digitale Transformatie en Professionele en Managed Services.